数据库笔记
数据库基础
基础概念
- 数据库(DB):存储数据的仓库
- 数据库管理软件(DBMS):管理数据库的软件(Oracle、MySQL、SQL server)
SQL
语法
- 不区分大小写
- ;结尾表示一句
数据类型
数
- tiny/small/medium/ int:1、2、3、4字节
- float/double(4,1):总长度为4,1位小数
字符串
- char(10):定长
- varchar(10):变长(最长为10)
日期时间
- date:2002-09-29
- time:18:20:12
- datetime:2002-09-29 18:20:12
DDL(definition)
数据库操作
1 | SHOW DATABASES; |
表操作
1 | SHOW TABLES; |
字段操作
1 | ALTER TABLE mymyfirstTable ADD nickname varchar(20); #添加字段 |
DML(manipulation)
1 | INSERT INTO mymyfirstTable(id,age) VALUES (1,1),(2,1); #添加数据 |
DQL(query)
1 | SELECT 字段列表 |
- 涉及到字符串相关,通常用like来操作
- group by的select后面通常只有groupby的字段和聚合函数,案例:统计男女分别有多少人
- 先where,再groupby,再having
DCL(control)
1 | CREATE USER 'cuixiu'@'localhost' IDENTIFIED BY '123456'; |
函数
字符串函数
- concat
- upper
- lower
- lpad(左填充)
- rpad(右填充)
- tram(去除前后空格)
- substring
日期函数
- now
- curdate
- curtime
- year(now())
- month(now())
- day(now())
- date_add(now(),INTERVAL 70 DAY) :相加
- datediff(now(),now()) :返回时间间隔的天数
数字函数
- ceil :天花板
- floor :地板
- round(0.12,1) :四舍五入,保留一位小数
- rand:返回0~1的随机数
- mod(x,y)
流程函数
- if(value,t,f) :如果value是true,返回t;否则返回f
- ifnull(value,t) :如果value不为空,返回value;否则返回t
- case when value then res1 else res2 :如果value为true,返回res1
- case expr when value then res1 else res2 :如果expr=value,返回res1
约束
建表时,字段名 字段类型 约束
- 非空约束
- 唯一约束
- 默认约束default
- 条件约束check
- 主键约束
- 外键约束
- 外键删除更新行为
- no action(不允许删除更新)
- district(不允许删除更新)
- cascade(级联删除更新)
- set null(设置子表的对应行的字段为null)
- 外键删除更新行为
1 | alter table myfirsttable add constraint person_dept_id foreign key (dept_id) references dept(id) |
多表查询
连接
- on来表示join的条件
- inner join :求交集
- left outer join :保留左边的全部和交集
- right outer join :保留右边的全部和交集
- 自连接:自己和自己join,必须要写两个不同的别名
1 | select a.name,b.name from person a join person b on a.upper_id=b.id; |
联合查询
求并集(左右两边必须是相同的列数和数据类型)
- union:去除重复
- union all:不去除重复
1 | select * from person |
子查询
- 标量子查询:通常用=、>、<等
- 列子查询:通常用in、> all、> any、> some等
- age > all(列子查询)
- 行子查询:通常用=
- (a,b,c) = 行子查询
- 表子查询
事务
- ACID:原子性、一致性、隔离性、持久性
- 一组操作的集合,不可再分的工作单位(银行转账)
1 | START TRANSACTION; |
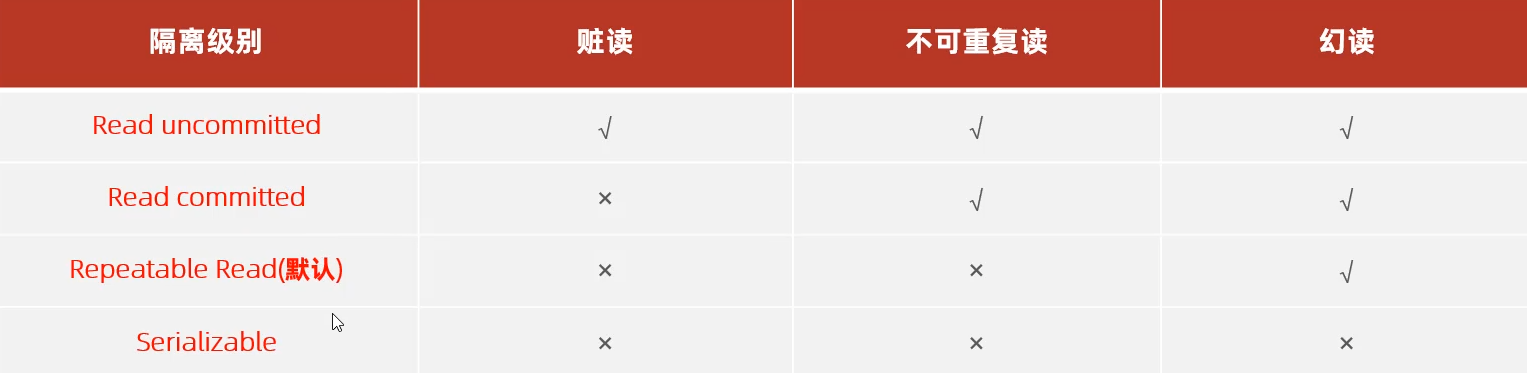
- 并发事务问题:脏读,不可重复读,幻读
- 隔离级别
1 | /* 设置隔离级别 */ |
数据库进阶
引擎
1 | CREATE TABLE mytable( |
- innodb:有事务、外键、行级锁
- myisam:表级锁,读和插入为主,并发性低,代替品:mongodb
- memory:存储在内存中,代替品:redis
索引
帮助mysql快速查找数据的数据结构
在存储引擎层实现,不同的引擎索引结构不同
优点:查找加快,
缺点:消耗空间,增删改速度变慢。
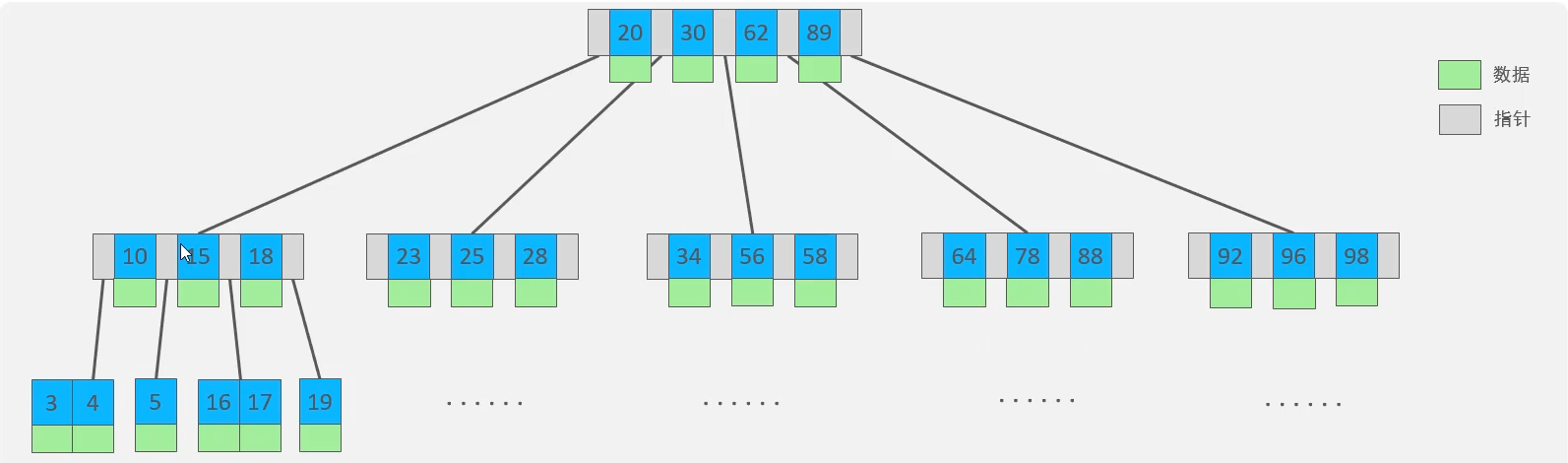
索引结构
二叉树:顺序插入时形成链表
红黑树(自平衡二叉树):数据量大时,层级太深
b树:中间元素向上分裂
- b+树:所有的元素都是叶子节点,叶子节点形成单向链表(树的高度更低)(MySQL优化:双向链表)
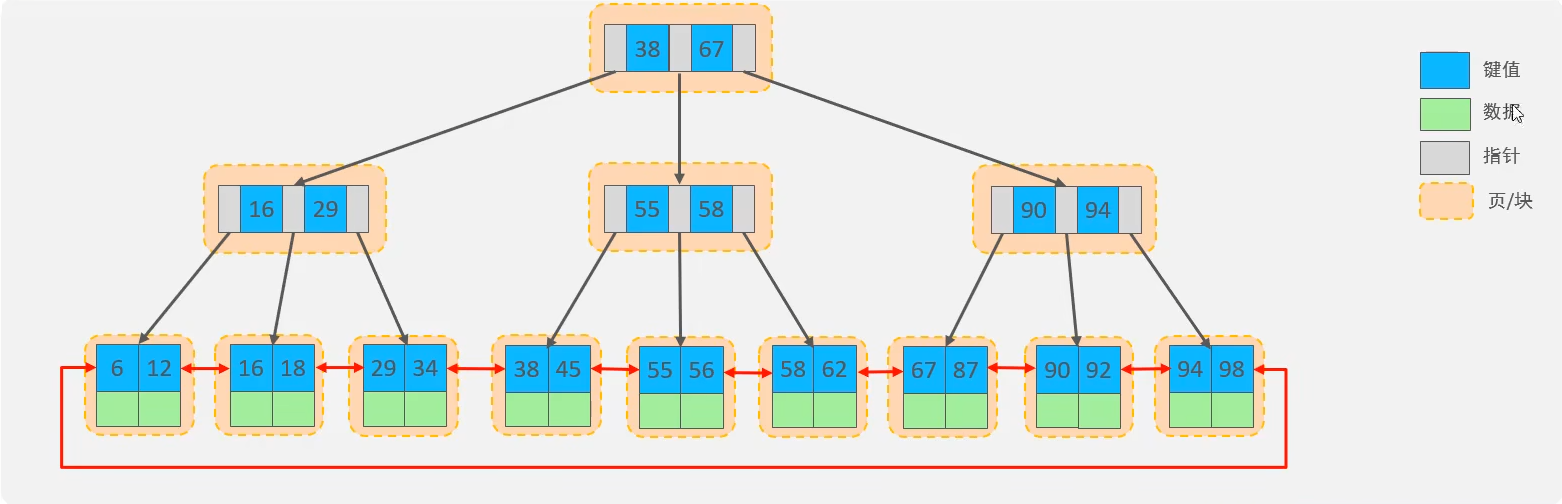
一个节点存在一页中(16k)
在联合索引中,按照a,b的顺序进行二级排列
hash:
只能用于等值匹配,不能进行范围查询
不能排序
查询效率高
索引分类
主键索引、唯一索引
聚集索引:叶子节点存储行的所有数据
- 有且只有一个
- 有主键则为主键,没有则为unique对应的索引
二级索引:叶子节点存储主键值
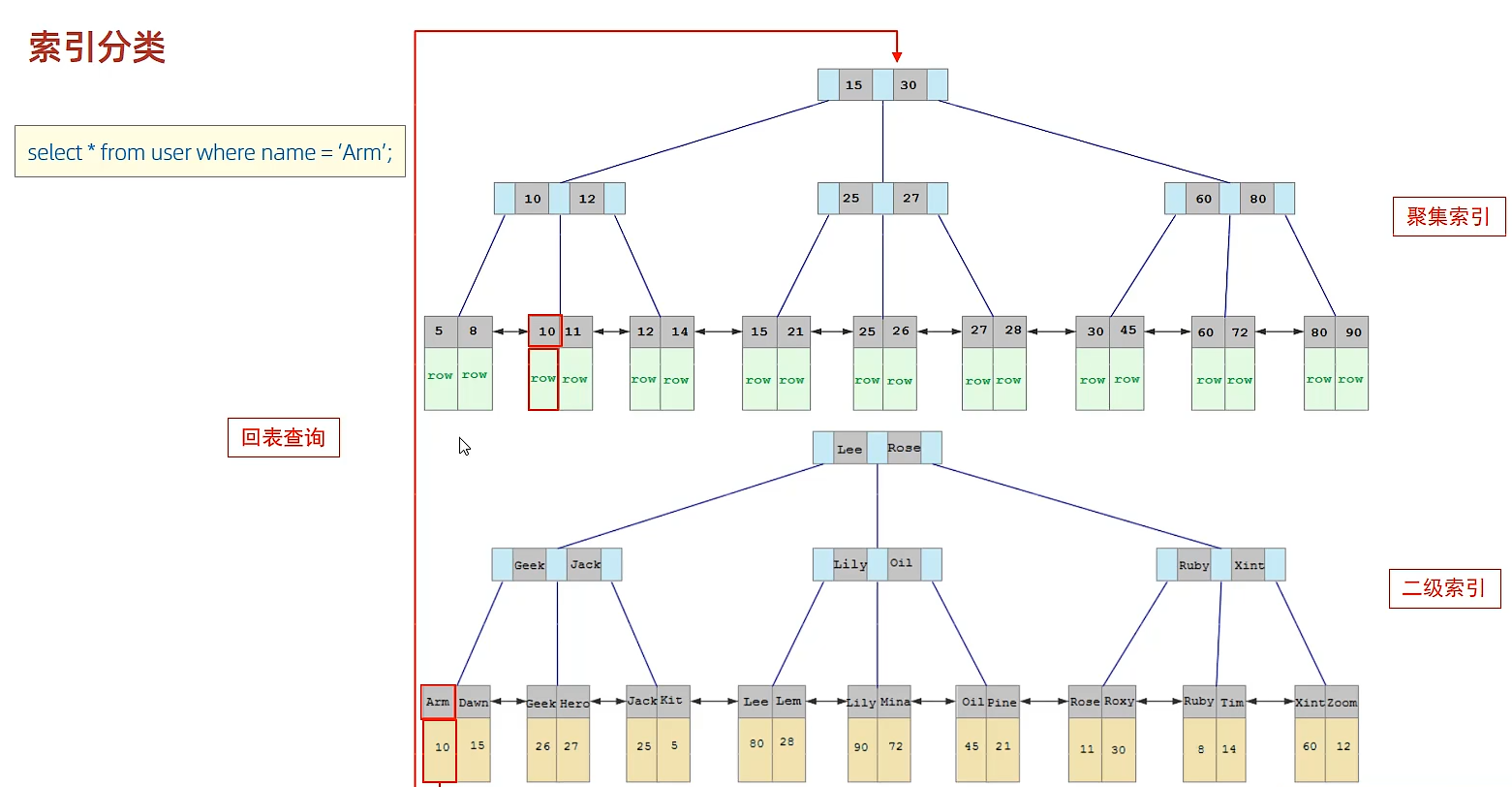
查找过程:先根据下面的二级索引找到主键,再根据主键去上面的聚集索引找这一行的所有值(回表查询)
语法
创建索引
1 | CREATE INDEX idx_user_name ON user(name,...); #可以创建联合索引 |
删除索引
1 | DROP INDEX idx_user_name FROM user; |
性能分析
查看执行频次
查看增删改查的执行频次
1 | SHOW GLOBAL STATUS LIKE 'COM_____' |
慢查询日志
记录了所有执行时间超过某个时间(slow_query_time)的sql语句记录
SHOW PROFILES
展示每一条sql的执行时间
EXPLAIN
1 | explain select ... |
索引使用原则
- 最左前缀法则:where条件里,联合索引中最左侧的索引必须存在
- 理解:索引代表着排序时按照最左侧的索引进行主排序,所以最左侧的索引必须存在
- 索引失效:索引列不要进行函数运算,字符串不加引号,like模糊匹配前边模糊匹配,全表扫描更快(数据分布)
- sql提示:select … use/ignore/force index(indexname) 强制sql使用/不使用某个索引
- 覆盖索引:查询返回的列都在索引中,不必回表查询
- 前缀索引:大文本字段时,建立前缀索引
- 单列/联合索引:联合索引使用得当,可以避免回表查询
SQL优化
insert优化
- 批量插入
- 开启事务,取消自动提交
- 按主键 ,顺序插入
- 大批量数据插入(load指令)
主键优化
数据存储方式
在innodb存储引擎中,表数据根据主键顺序存储
表数据存储在页中,一页存储2-n行数据
页分裂
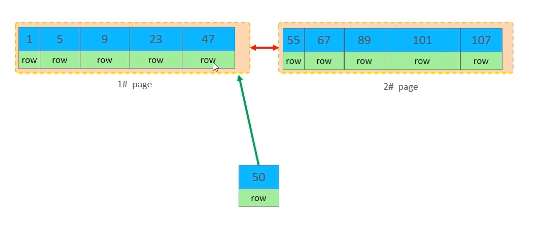
把23和47移动到一个新页中,页的链表顺序也要改变

页合并
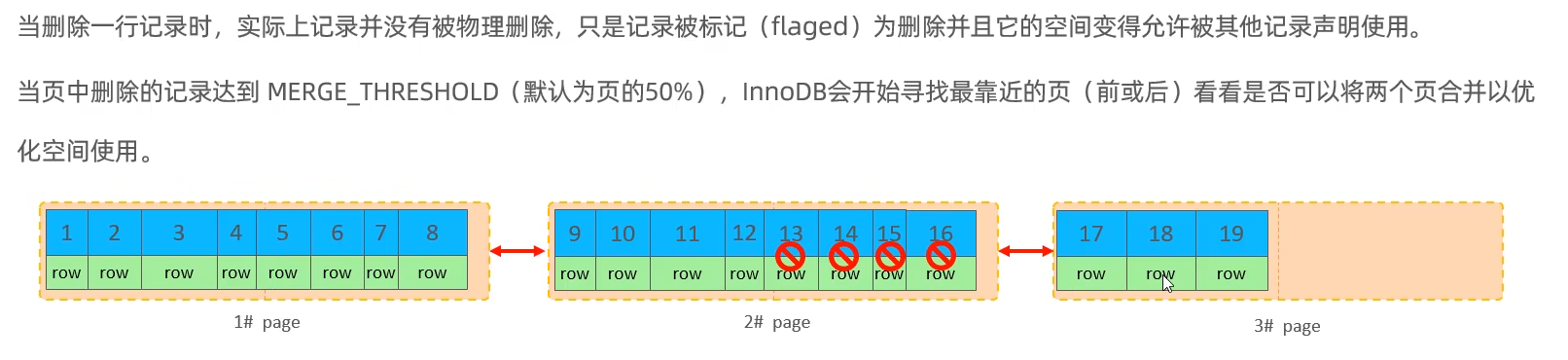
主键优化要求
- 尽可能按主键顺序插入(自增)
- 尽量不要用uuid
- 主键的长度尽可能短(节省二级索引所占的空间)
- 尽量避免修改主键
OrderBy优化
两种排序方式
- using filesort:全表扫描,使用排序算法
- using index:使用已经排好序的索引
orderby优化要求
- 尽量使用覆盖索引
- 使用排序字段建立合适的索引,多字段索引遵循最左前缀法则
- 多字段排序,如果一个升序一个降序,创建索引时可以声明升序和降序
- 如果不可避免出现filesort,大数据量排序时,可以适当增大排序缓冲区的大小sort_buffer_size
GroupBy优化
我的理解
如果有索引,只用扫描一遍;没有索引,就要全表扫描
- using temporary:使用临时表
- using index:使用索引
groupby优化要求
在groupby的字段添加索引
limit优化
- limit 9000000,10意味着先给前9000010条数据排序,然后返回9000000-9000010的数据,很慢
- 通常采用覆盖索引+子查询
count优化
- count(*):不取值,直接累加
- count(1):不取值,放1进去,直接累加
- count(字段):取字段值,判断是否为null,不为null再累加
- count(主键):取主键值,直接累加(肯定非空)
- 效率:count(字段)<count(主键)<count(*)=count(1)
update优化
update的where字段最好有索引,否则锁会从行锁变成表锁
视图
基本操作
1 | /* 增 */ |
view:记录了某条代表一些表的sql语句,并不真正存储表,方便进行操作
检查选项
with check cascaded/local option :检查选项,当对视图进行添加/修改数据时,是否检查视图定义中where的条件以及父视图的where条件
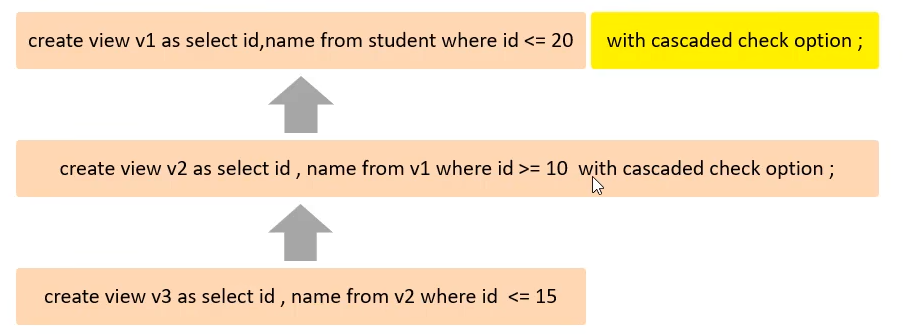
cascade:检查时必须检查父类
local:检查时递归地检查父类,如果父类有with check option,就也检查,否则不坚持
作用
- 简单,简化用户的一些常用操作
- 安全,控制用户的访问
- 数据独立,屏蔽基表的变化对用户的影响
存储过程
存储过程是事先经过编译并存储在数据库中的一系列SQL语句的集合,调用存储过程可以简化应用开发人员的很多操作,减少数据在数据库和应用服务器之间的传输。
可以接收参数,也可以返回数据
基本操作
1 | /* 创建 */ |
变量
系统变量
- session 会话变量,一个控制台是一个会话
- global 全局变量
1 | /* 展示系统变量 */ |
用户变量
1 | /* 定义 */ |
局部变量
存储过程begin-end之间的变量
1 | create procedure p1 () |
if
1 | create procedure p1 () |
参数(输入输出)
1 | /* in out */ |
case语句
1 | create procedure p1 (in month int,out result varchar(10)) |
while语句
1 | create procedure p1 (in n int,out result int) |
repeat语句
1 | create procedure p1 (in n int,out result int) |
loop语句
1 | create procedure p1 (in n int,out result int) |
游标cursor
游标是存储查询结果集的数据类型
1 | create procedure p1 () |
条件处理程序
当存储过程发生警告/错误时的处理办法 —— 继续执行continue/中止exit
1 | declare continue/exit handle for sqlstate '02000' close mycursor; /* close mycursor是指exit之前还要做什么事 */ |
存储函数
有返回值的存储过程。参数只能是in类型。
1 | create function f1(n int) |
触发器
触发器是指在insert,update,delete之前或之后,触发并执行触发器中定义的SQL语句的集合
- 确保数据的完整性
- 日志记录
- 数据校验

insert触发器
1 | /* 插入后更新日志表 */ |
update触发器
1 | /* 插入后更新日志表 */ |
delete触发器
1 | /* 插入后更新日志表 */ |
锁
全局锁
对整个数据库加锁,加锁后整个实例处于只读状态,DDL\DML语句都将阻塞
典型场景:对数据库进行备份,对所有的表进行锁定,保证数据的完整性
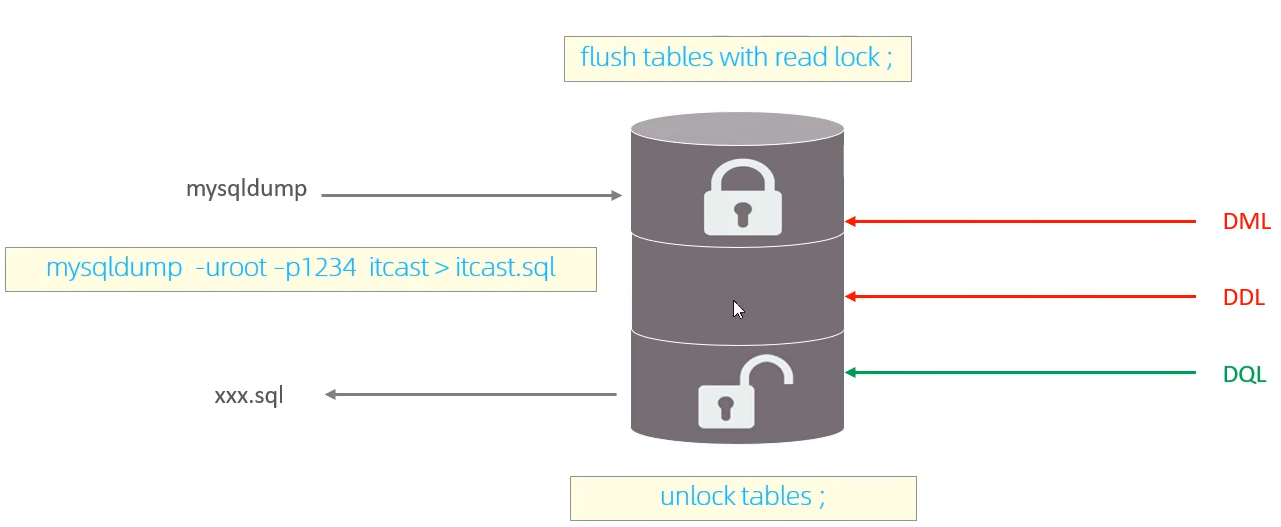
mysqldump代表备份
缺点:业务停摆。在innodb引擎中,可以通过在mysqldump命令中加入 –single-transaction来完成备份
表级锁
表锁
- 读锁:只能读不能写(都能读)
- 写锁:只能自己进行读写
1 | /* 读锁 */ |
元数据锁MDL(自动)

增删改查的时候,加mdl读锁(共享);修改表的时候,加mdl写锁(排他)
代表着,一个客户端增删改查,另一个客户端也可以增删改查,但是不能修改表;一个客户端修改表,另一个客户端什么都不能做
意向锁(自动)
加行锁时自动加,减少表锁的检查(当a加了行锁,b要加表锁时,由于a加行锁后自动加意向锁,所以不必一行一行的检查)
- 意向共享锁(IS):select … lock in share mode时自动加,和表锁中的读锁兼容
- 意向互斥锁(IX):select … for update、insert、update、delete时自动加,都不兼容
行级锁
行锁(自动)
针对索引上的索引项来加锁,在RC和RR级别下支持
- 共享锁(S):可以一起读
- 排他锁(X):只能自己读写

innodb引擎的行锁是针对索引加的,有索引时才会加行锁,没有索引时就会自动变成表锁
间隙锁(自动)和nextkey临键锁(自动)
保证间隙不变,(不能在间隙锁的那个间隙中增删改),在RR隔离级别下支持,可以防止幻读
- 唯一索引,等值查询,给不存在的记录加锁时,自动优化为间隙锁
- 普通索引,等值查询,临键锁退化为间隙锁
- 唯一索引,范围查询,加临键锁
一些理解
展示锁
1
select object_schema,object_name,index_name,lock_type,lock_mode,lock_data from performance_schema.data_locks;
插入数据时,自动加行锁和意向锁
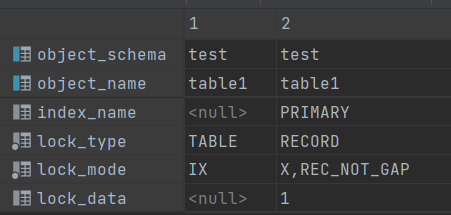
如图,插入数据时创建的锁,IX为意向锁(TABLE),X,REC为行锁
除了全局锁和表锁,剩下的都是在增删改和改变表结构时自动加的
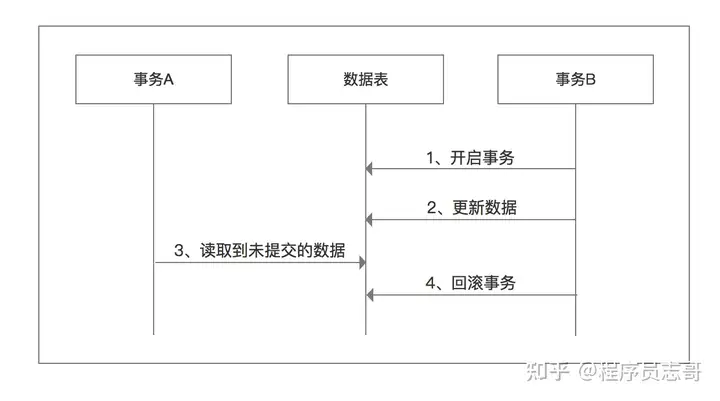
脏读、幻读、不可重复读
脏读:不提交就能读
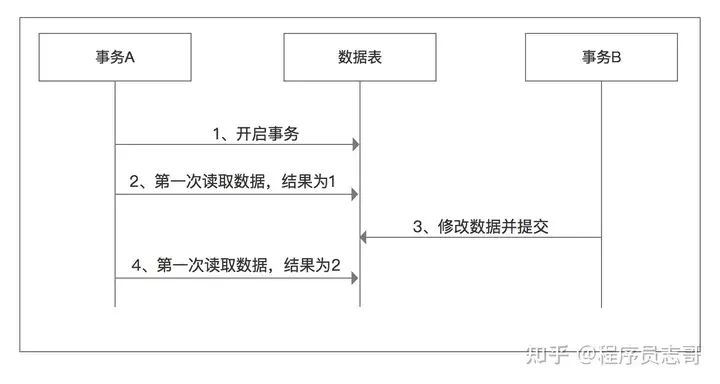
不可重复读:提交了才能读
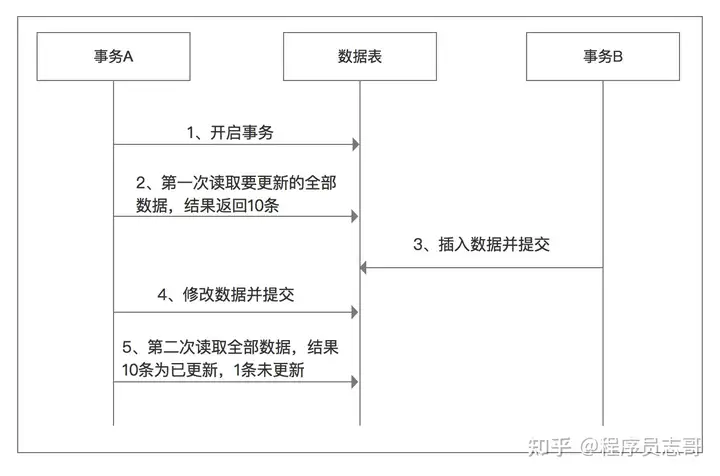
幻读:幻读就是事务在做范围查询(SELECT)的过程中,有另外一个事务对范围内新增了记录(INSERT),导致范围查询的结果条数不一致的现象。
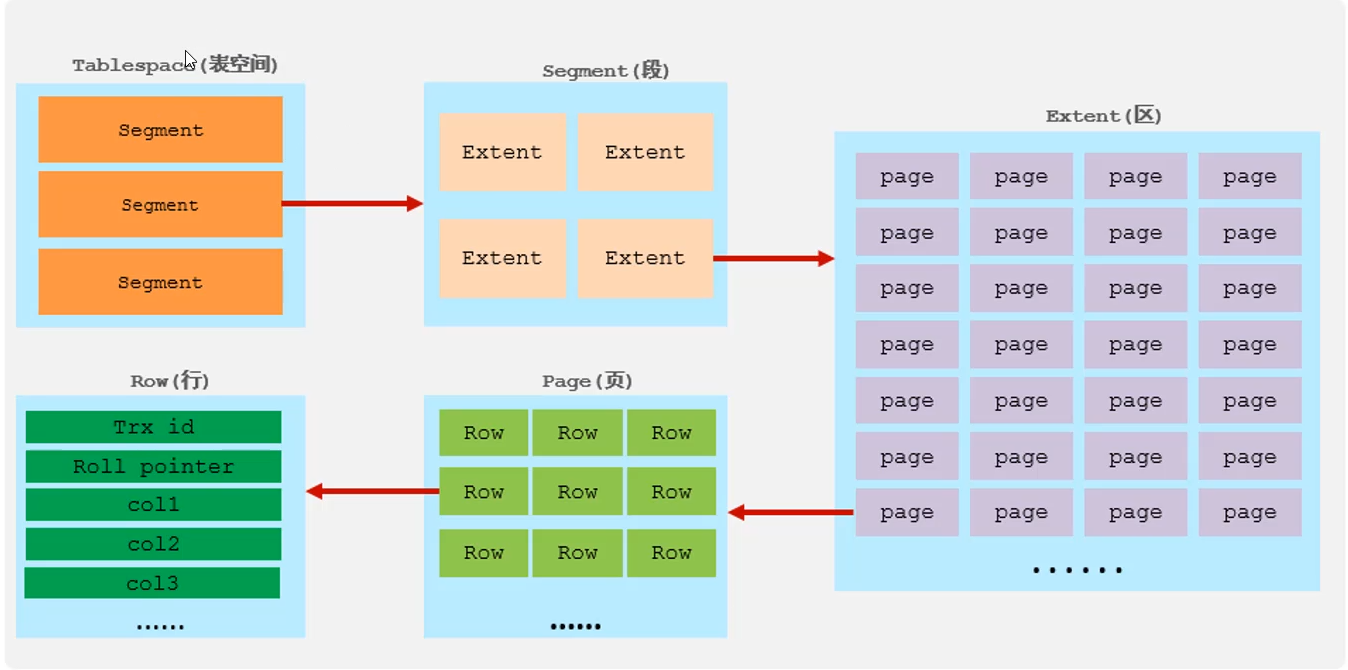
InnoDB引擎
逻辑结构
内存结构
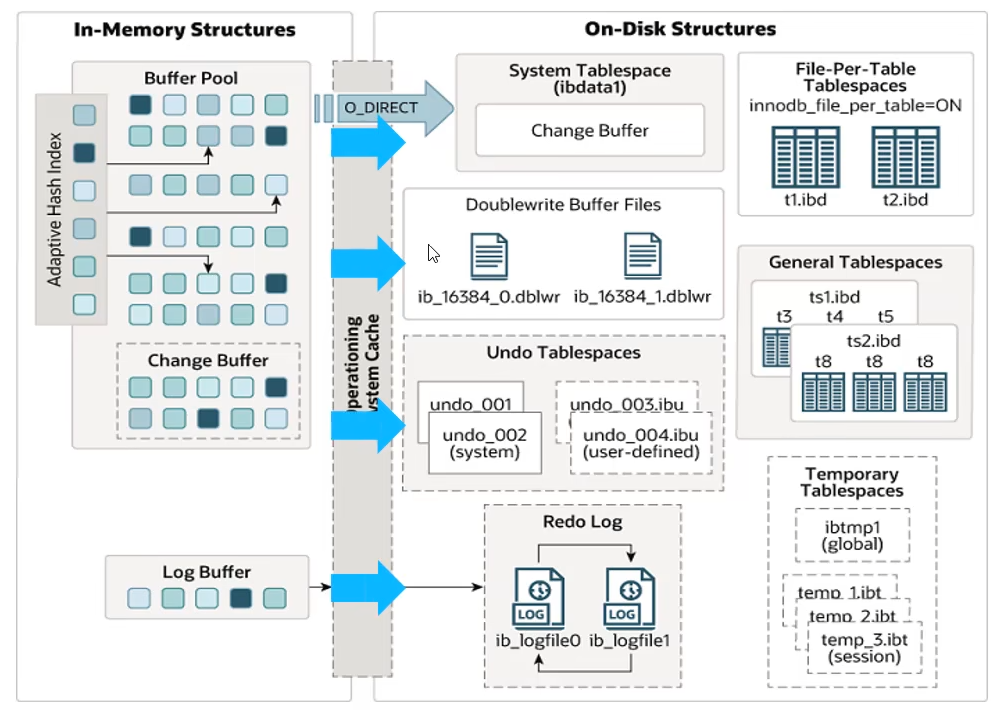
Buffer Pool
缓冲池 Buffer Pool,是主内存中的一个区域,里面可以缓存磁盘上经常操作的真实数据,在执行增删改查操作时,先操作缓冲池中的数据(若缓冲池没有数据,则从磁盘加载并缓存),然后再以一定频率刷新到磁盘,从而减少磁盘IO,加快处理速度。 缓冲池以Page页为单位,底层采用链表数据结构管理Page。
根据状态,将Page分为三种类型:
- free page:空闲page,未被使用。
- clean page:被使用page,数据没有被修改过。
- dirty page:脏页,被使用page,数据被修改过,也中数据与磁盘的数据产生了不一致。
Change Buffer
Change Buffer,更改缓冲区(针对于非唯一二级索引页),在执行DML语句时,如果这些数据Page没有在Buffer Pool中,不会直接操作磁盘,而会将数据变更存在更改缓冲区 Change Buffer 中,在未来数据被读取时,再将数据合并恢复到Buffer Pool中,再将合并后的数据刷新到磁盘中。
与聚集索引不同,二级索引通常是非唯一的,并且以相对随机的顺序插入二级索引。同样,删除和更新 可能会影响索引树中不相邻的二级索引页,如果每一次都操作磁盘,会造成大量的磁盘IO。有了 ChangeBuffer之后,我们可以在缓冲池中进行合并处理,减少磁盘IO。
Adaptive hash index
自适应hash索引,用于优化对Buffer Pool数据的查询。MySQL的innoDB引擎中虽然没有直接支持 hash索引,但是给我们提供了一个功能就是这个自适应hash索引。hash索引在进行等值匹配时,一般性能是要高于B+树的,因为hash索引一般只需要一次IO即可,而B+树,可能需要几次匹配,所以hash索引的效率要高,但是hash索引又不适合做范围查询、模糊匹配等。 InnoDB存储引擎会监控对表上各索引页的查询,如果观察到在特定的条件下hash索引可以提升速度, 则建立hash索引,称之为自适应hash索引。
Log Buffer
日志缓冲区,用来保存要写入到磁盘中的log日志数据(redo log 、undo log), 默认大小为 16MB,日志缓冲区的日志会定期刷新到磁盘中。如果需要更新、插入或删除许多行的事 务,增加日志缓冲区的大小可以节省磁盘 I/O。
磁盘结构
System Tablespace
系统表空间是更改缓冲区的存储区域。如果表是在系统表空间而不是每个表文件或通用表空间中创建的,它也可能包含表和索引数据。(在MySQL5.x版本中还包含InnoDB数据字典、undolog等)
File-Per-Table Tablespaces
如果开启了innodb_file_per_table开关 ,则每个表的文件表空间包含单个InnoDB表的数据和索引 ,并存储在文件系统上的单个数据文件中。
General Tablespaces
通用表空间,需要通过 CREATE TABLESPACE 语法创建通用表空间,在创建表时,可以指定该表空间。
Undo Tablespaces
撤销表空间,MySQL实例在初始化时会自动创建两个默认的undo表空间(初始大小16M),用于存储undo log日志。
Temporary Tablespaces InnoDB
使用会话临时表空间和全局临时表空间。存储用户创建的临时表等数据。
Doublewrite Buffer
双写缓冲区,innoDB引擎将数据页从Buffer Pool刷新到磁盘前,先将数据页写入双写缓冲区文件中,便于系统异常时恢复数据。
Redo Log
重做日志,是用来实现事务的持久性。该日志文件由两部分组成:重做日志缓冲(redo log buffer)以及重做日志文件(redo log),前者是在内存中,后者在磁盘中。当事务提交之后会把所有修改信息都会存到该日志中, 用于在刷新脏页到磁盘时,发生错误时, 进行数据恢复使用。
后台线程
Master Thread
核心后台线程,负责调度其他线程,还负责将缓冲池中的数据异步刷新到磁盘中, 保持数据的一致性, 还包括脏页的刷新、合并插入缓存、undo页的回收 。
IO Thread
在InnoDB存储引擎中大量使用了AIO来处理IO请求, 这样可以极大地提高数据库的性能,而IO Thread主要负责这些IO请求的回调。
Purge Thread
主要用于回收事务已经提交了的undo log,在事务提交之后,undo log可能不用了,就用它来回收。
Page Cleaner Thread
协助 Master Thread 刷新脏页到磁盘的线程,它可以减轻 Master Thread 的工作压力,减少阻塞。
事务原理
redo log
重做日志,记录的是事务提交时数据页的物理修改,是用来实现事务的持久性。
该日志文件由两部分组成:重做日志缓冲(redo log buffer)以及重做日志文件(redo log file),前者是在内存中,后者在磁盘中。
当事务提交之后会把所有修改信息都存到该日志文件中, 用 于在刷新脏页到磁盘,发生错误时, 进行数据恢复使用。
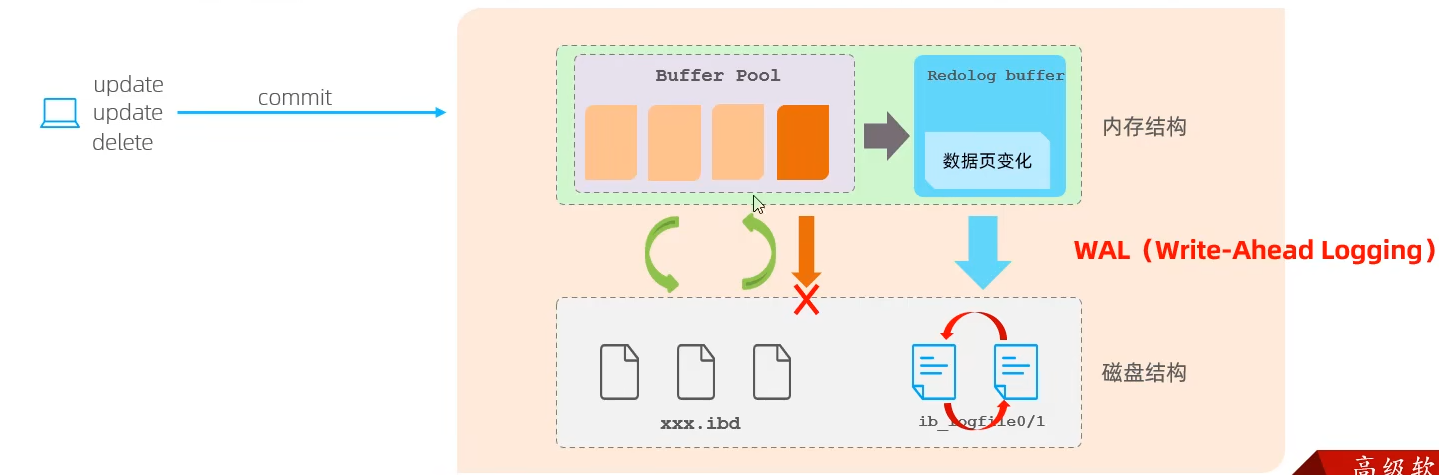
- 当bufferpool中的数据写入失败时,redolog可以恢复写入
- redolog属于顺序修改,直接写入输入随机修改,顺序修改可以减少磁盘io
undo log
回滚日志,用于记录数据被修改前的信息 , 作用包含两个 : 提供回滚(保证事务的原子性) 和 MVCC(多版本并发控制) 。
undo log和redo log记录物理日志不一样,它是逻辑日志。可以认为当delete一条记录时,undo log中会记录一条对应的insert记录,反之亦然,当update一条记录时,它记录一条对应相反的 update记录。当执行rollback时,就可以从undo log中的逻辑记录读取到相应的内容并进行回滚。
MVCC版本并发控制
维护一个数据的多个版本
- 当前读:保证读到的是最新版本,即控制其他事务不能修改当前记录。insert、update、delete、select…lock in share mode、select…for update。
- 快照读:读的是数据的快照(不一定是当前版本)。单纯的select。
- read commited:提交了就能读到。每次读都生成一个快照读
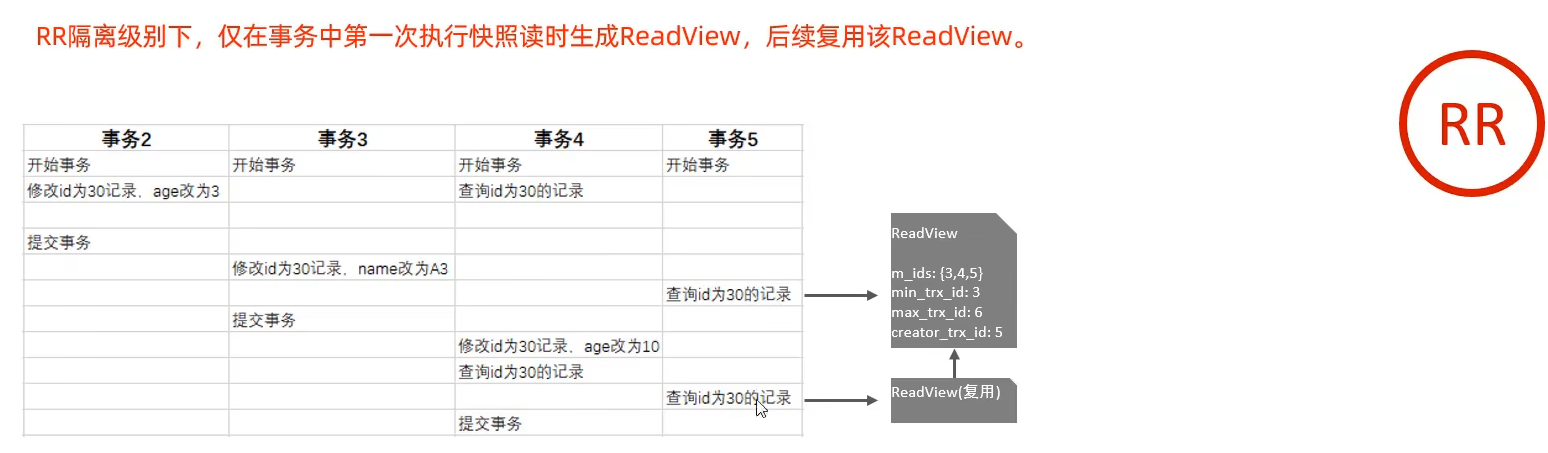
- read repeatable:读到的永远是事务开启时第一次读的版本。开启事务后第一个select语句生成快照读
- serializable:读阻塞,每次读,其他的都不能写。
实现原理
隐藏字段

undolog 版本链
undolog中记录着数据的版本
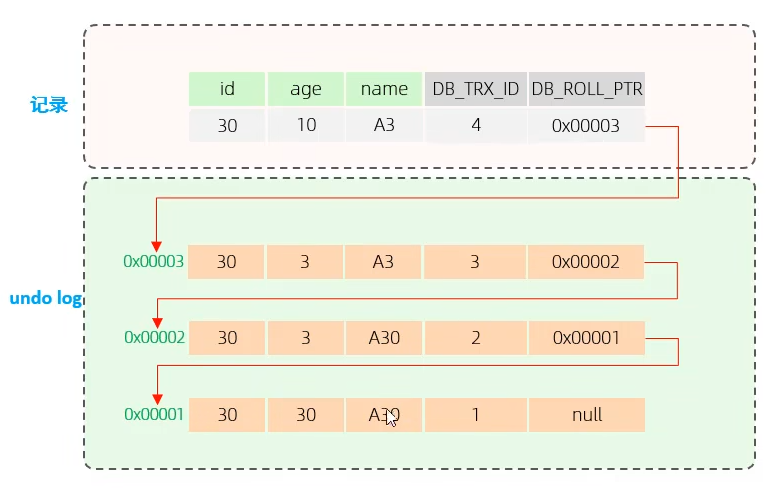
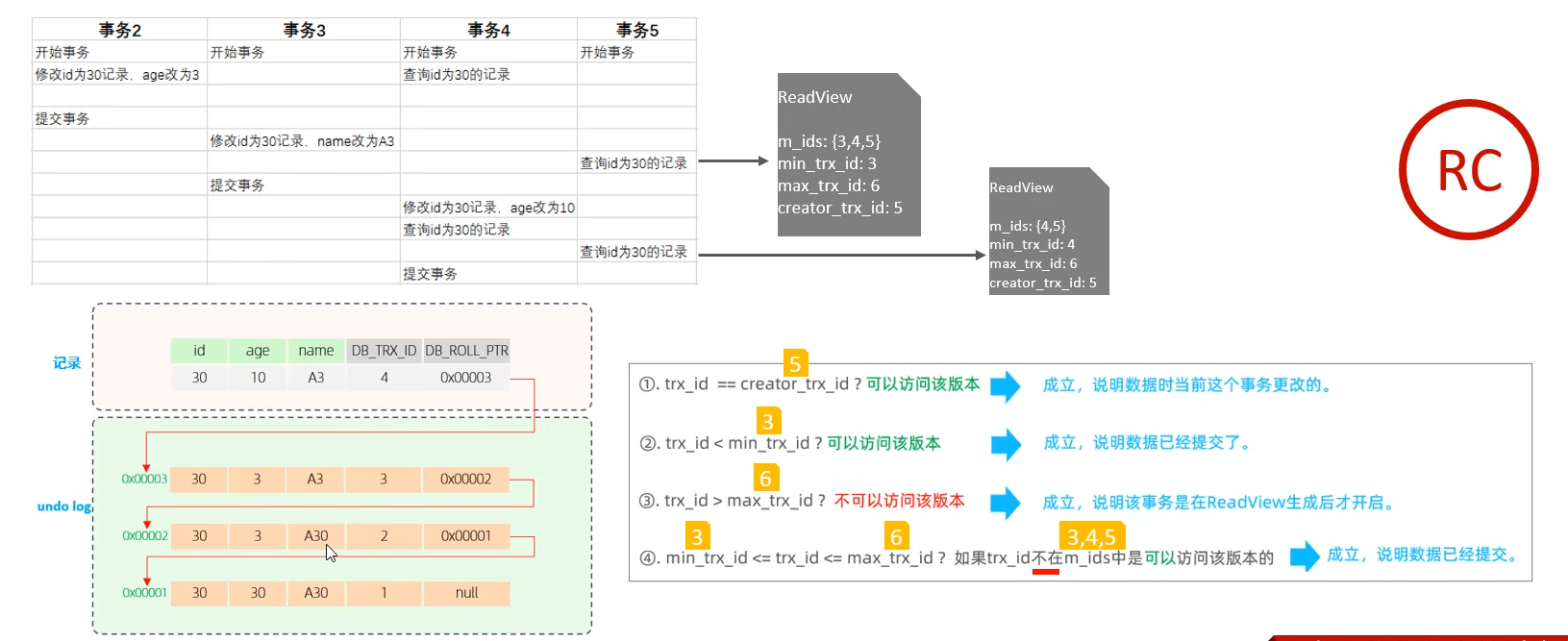
readview
快照读就会生成readview,rc级别下每一次读都生成readview,rr级别下仅第一次读生成readview,通过readview的字段与数据版本链中的隐藏字段对比,即可知道要读的是哪个版本

rc
rr
数据库运维篇
日志
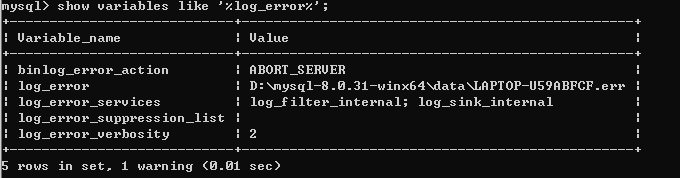
错误日志
记录mysql启动和停止时,以及服务器在运行中发生严重错误的错误信息
1 | /* 查看错误日志的位置 */ |
二进制日志
记录了所有的DDL和DML语句,不包含DQL语句
- 灾难时的数据恢复
- mysql主从复制
1 | /* 查看二进制日志的位置 */ |

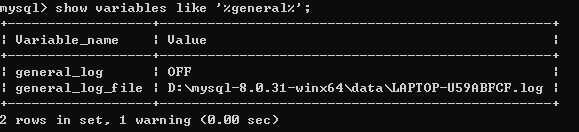
查询日志
记录mysql的所有操作
1 | /* 查看二进制日志的位置 */ |
慢查询日志
记录了mysql中所有时间超过time,记录数大于mincount的操作
1 | #(my.inf) |
主从复制
主从复制是指将数据库的DDL语句和DML语句通过日志传送到从数据库服务器中,并对这些日志重新执行,从而使从库和主库保持一致
- 主库出现问题
- 备份从库
- 读写分离,降低压力
原理
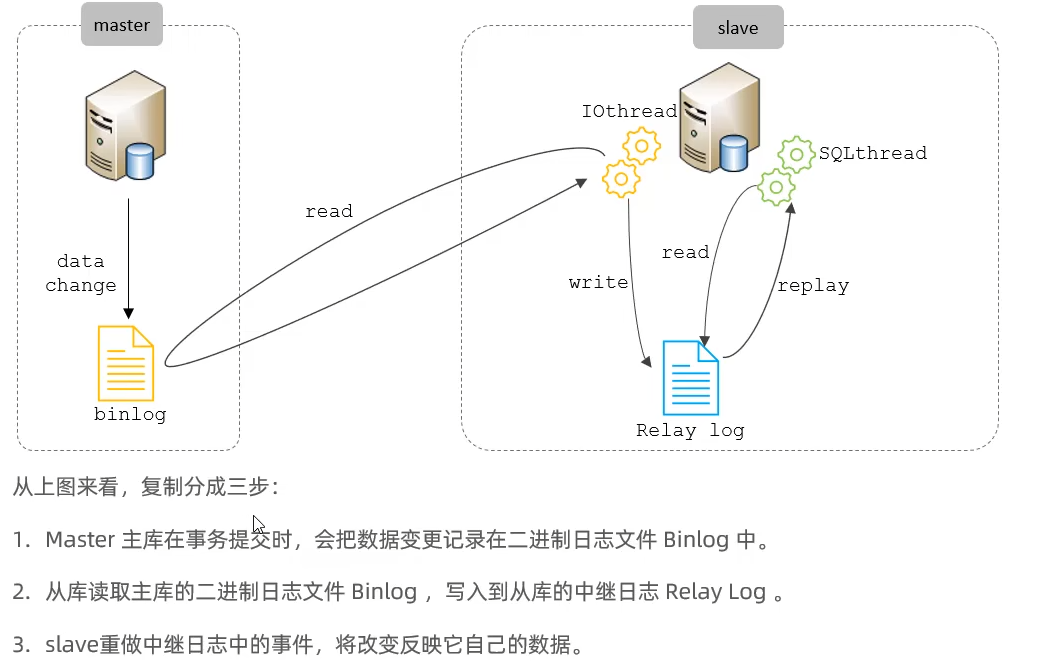
主库配置
- 修改my.cnf

重启mysql服务
创建新用户

展示保存的二进制文件及其位置
从库配置
修改my.cnf

重启mysql服务
配置主库信息

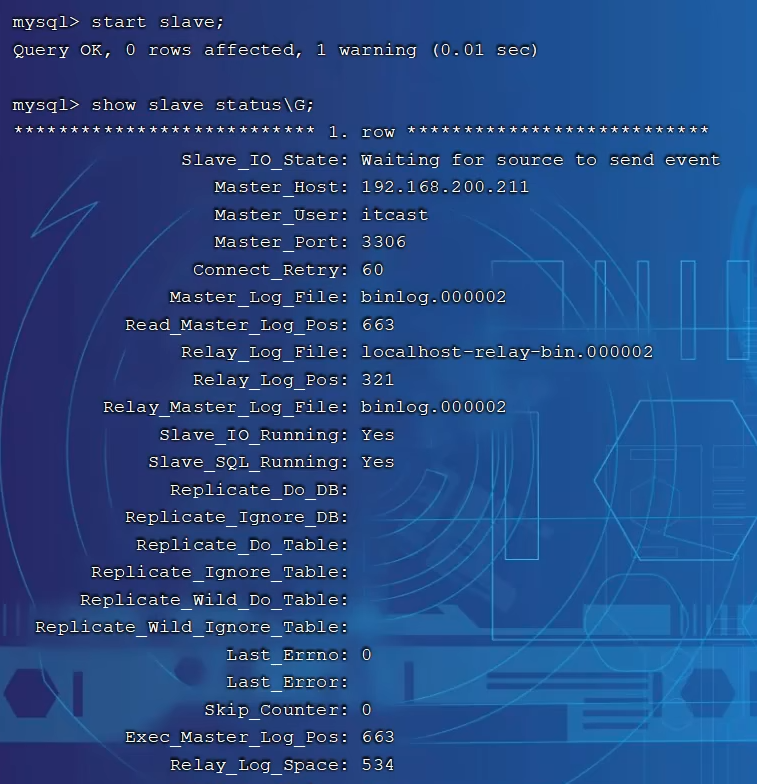
开启同步操作

查看同步信息(iorunning代表io线程传输,sqlrunning代表sql线程执行日志操作)

分库分表
单数据库:
- IO瓶颈:磁盘IO,网络IO
- CPU瓶颈:大量消耗cpu资源
拆分方式
垂直拆分
一张库分成多张库,一张表分成多张表
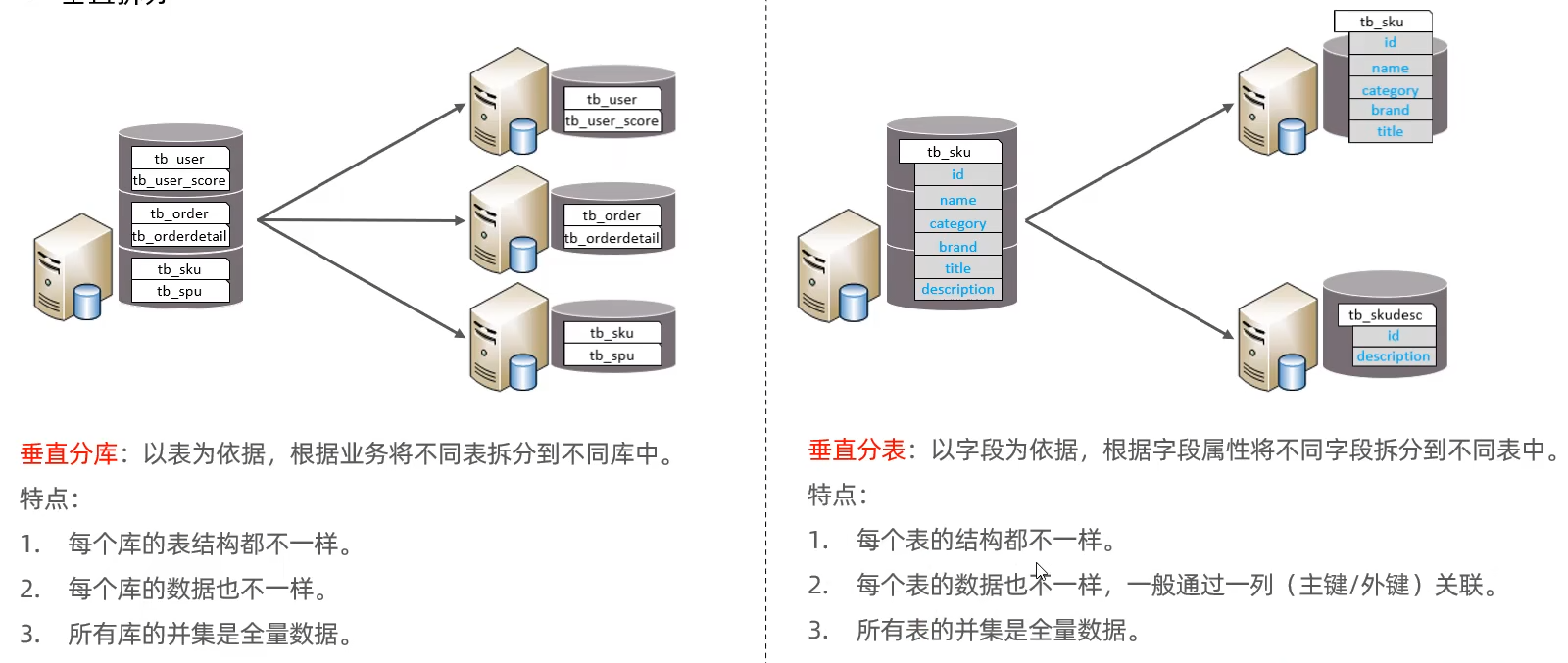
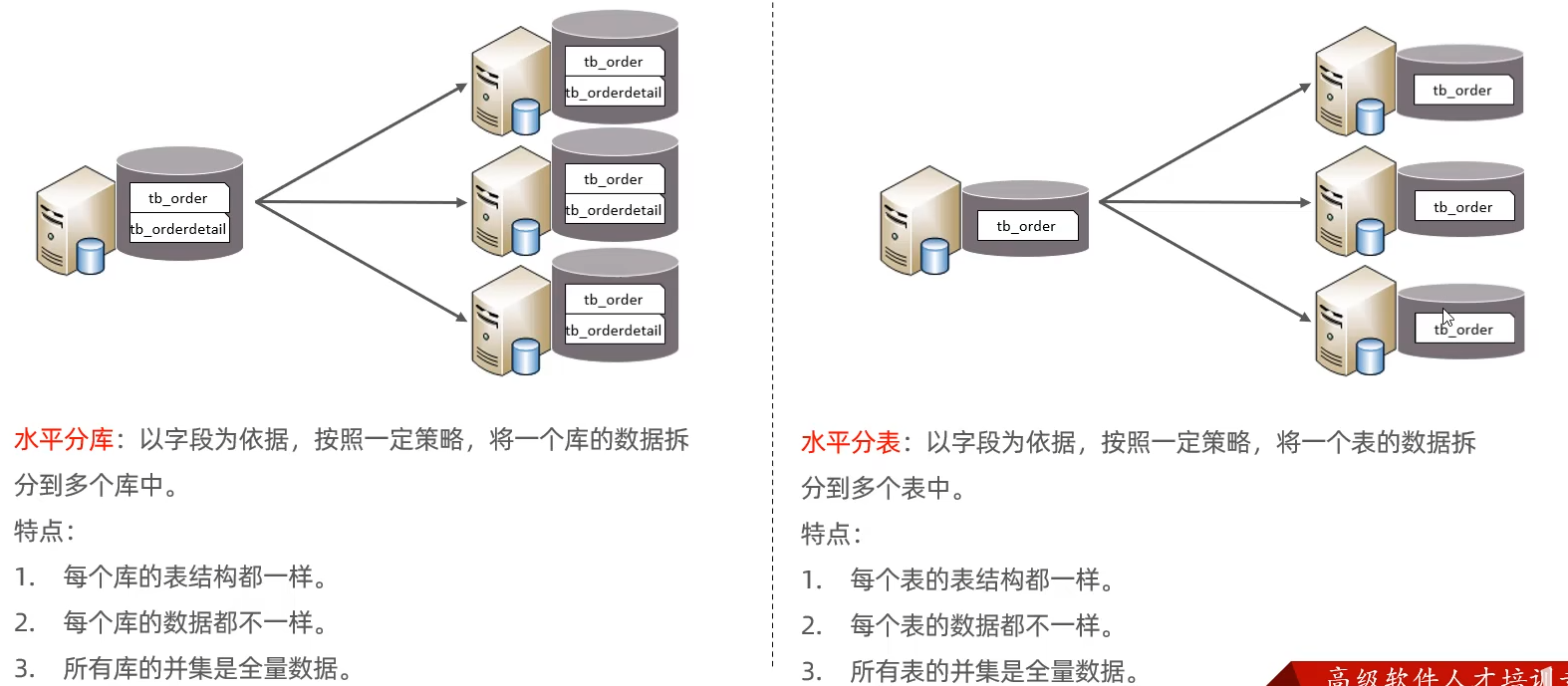
水平拆分
一个库的数据分散在三个库中,一个表的数据分散在三个表中(编码难度加大)
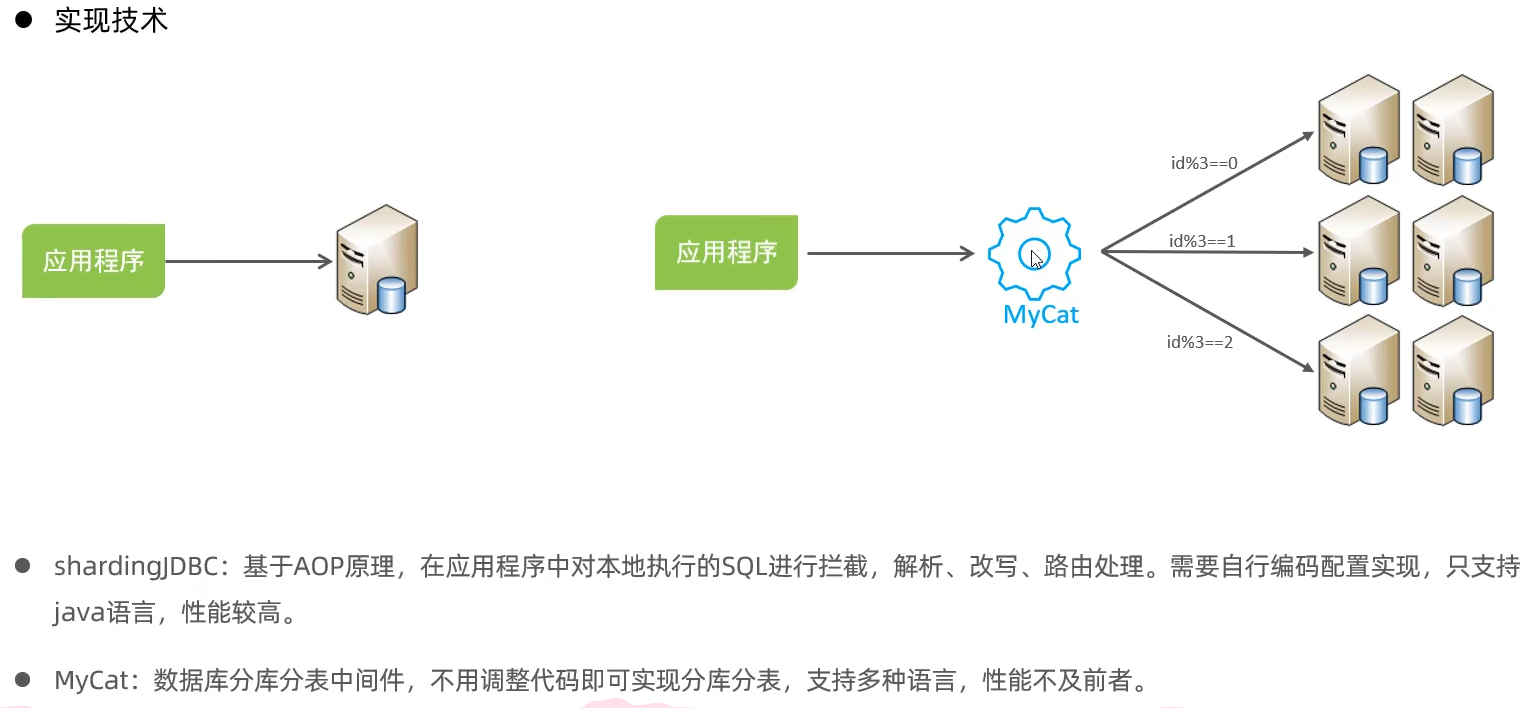
实现方式
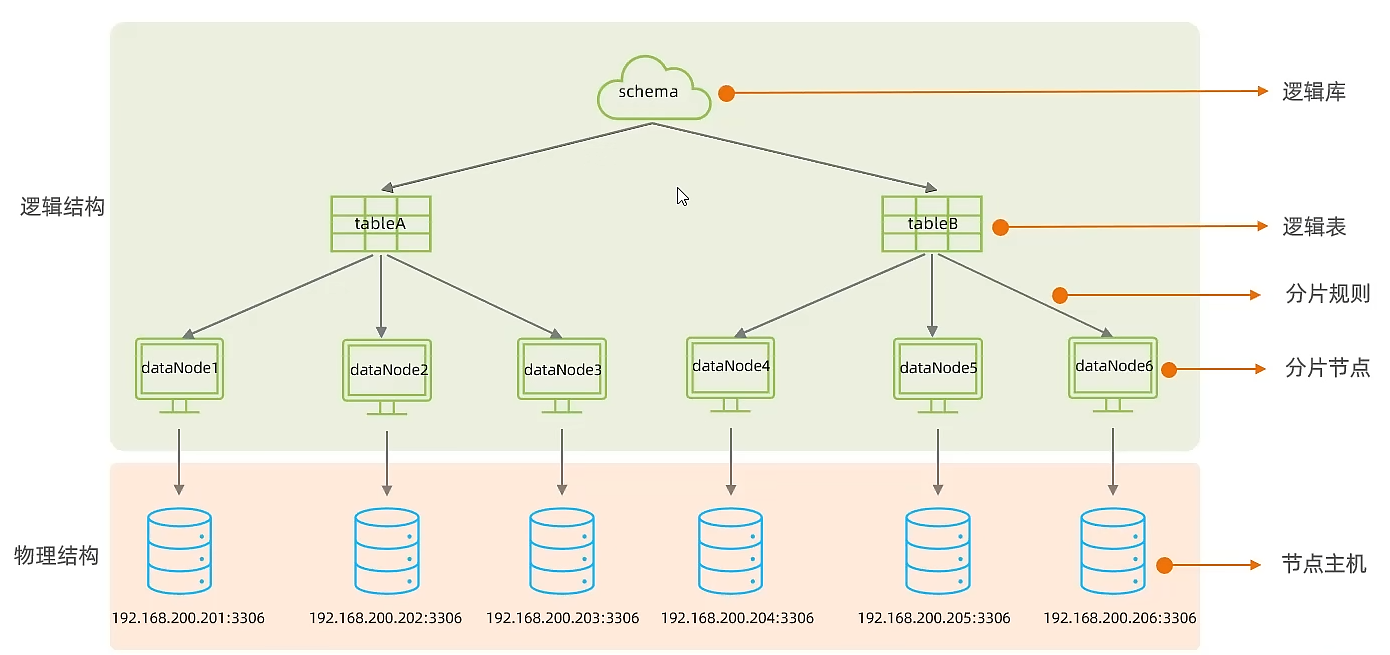
mycat中间件
逻辑结构
mycat不存储数据,数据存储在物理数据库中
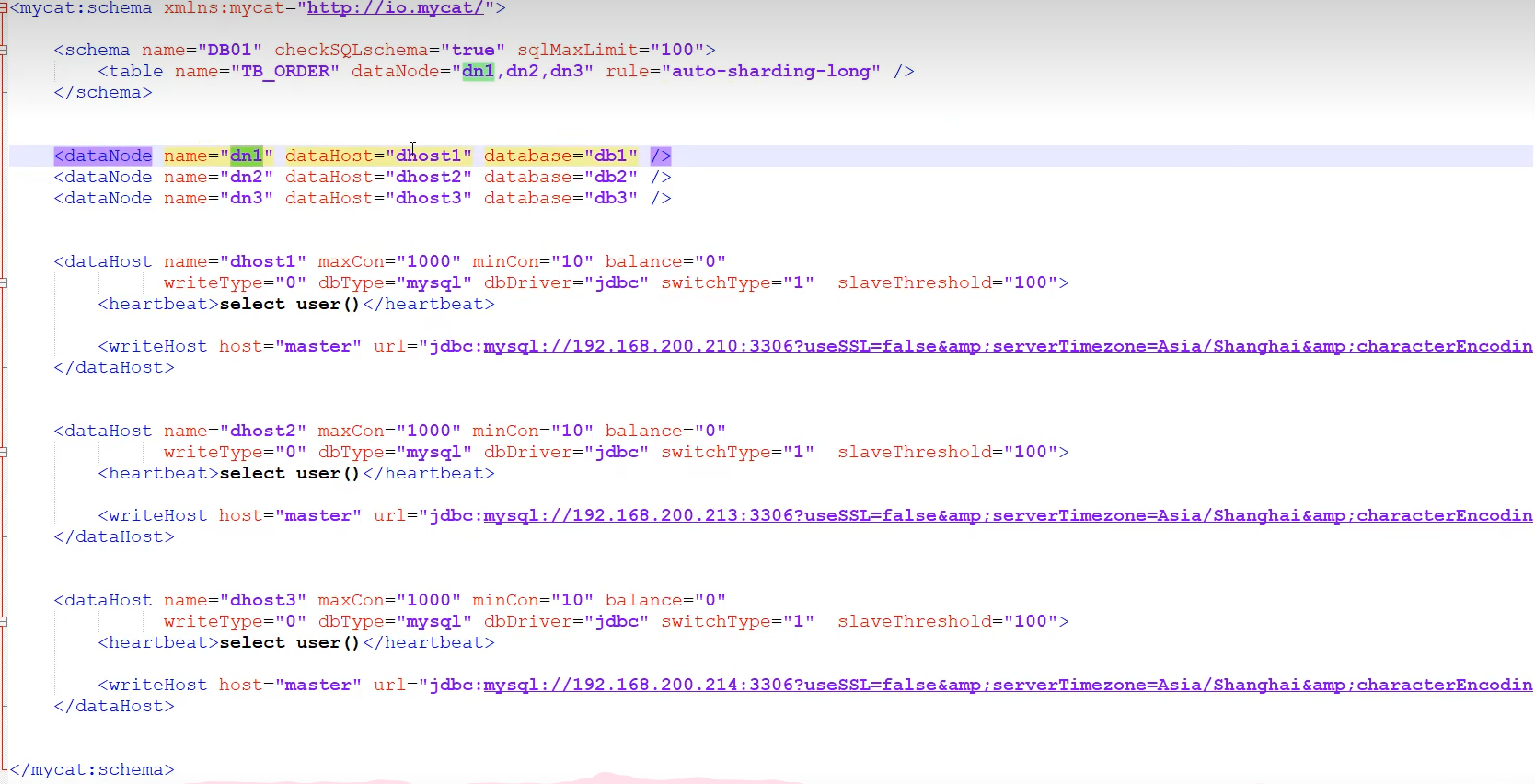
用法
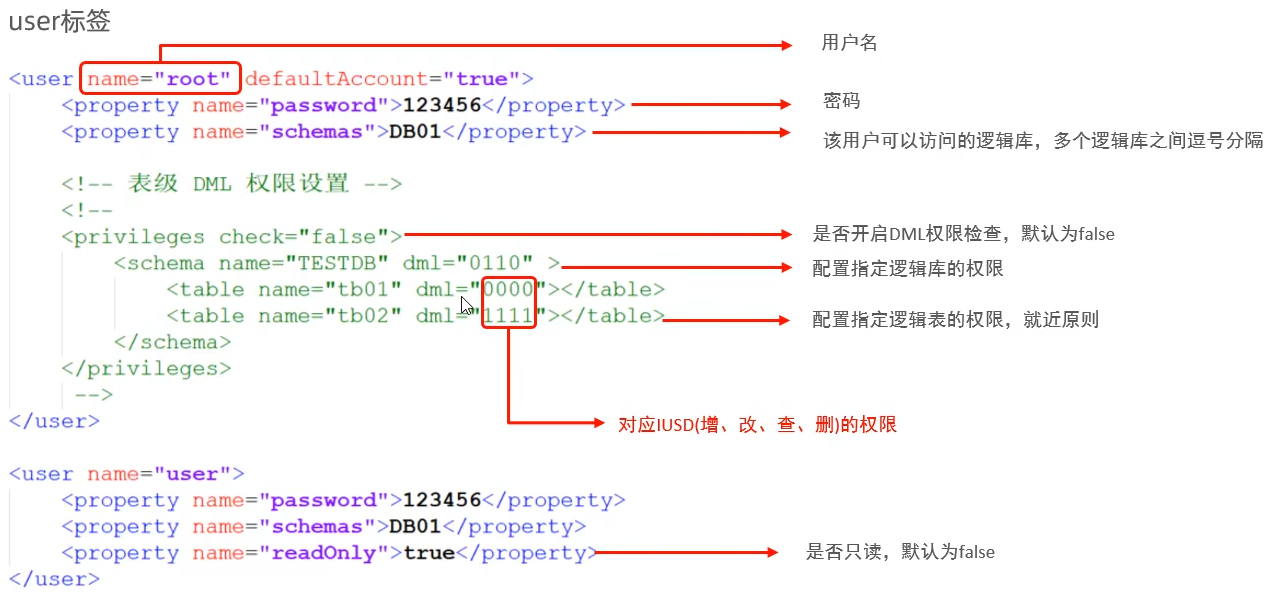
修改schema.xml(配置结点数据库)
配置server.xml(配置mycat用户信息)
启动服务
1
2start;
stop;连接mycat
1
2mysql -u root -P 8066
操作数据库即可(把mycat当成一个数据库,不用管底层)
案例
垂直分库

多表联查如果跨越多个服务器,不可行,解决办法是设置全局表(每个服务器都有相应的表) ——type=”global”
分片规则
rule.xml
schema中配置逻辑表时有rule字段,选择了表的分片规则,分片规则定义在rule.xml中
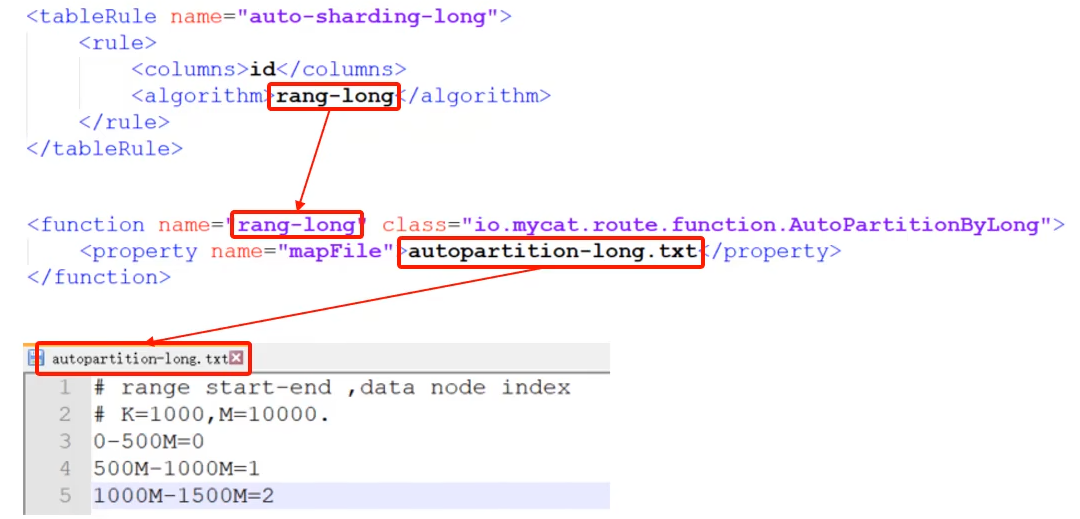
范围分片
根据指定的字段的范围与数据结点的对应情况,来进行分片

取模分片
根据指定的字段的范围与数据结点数量的取模值,来进行分片
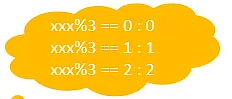
一致性哈希
根据指定的字段的哈希计算值来进行分片

枚举分片
根据指定字段的值,与配置文件中的枚举规则,进行分片(性别、省份)

应用指定
在运行中由应用指定,进行分片(通常用substring)

固定分片hash算法
类似取模,比如说,某个字段的二进制与1111111111进行位与运算得到低十位,然后再进行范围分片(与取模相比,连续值可以在同一个分片上)
字符串hash解析算法

按天分片
每十天一片

按月分片
每个月一片

mycat管理与监控
原理
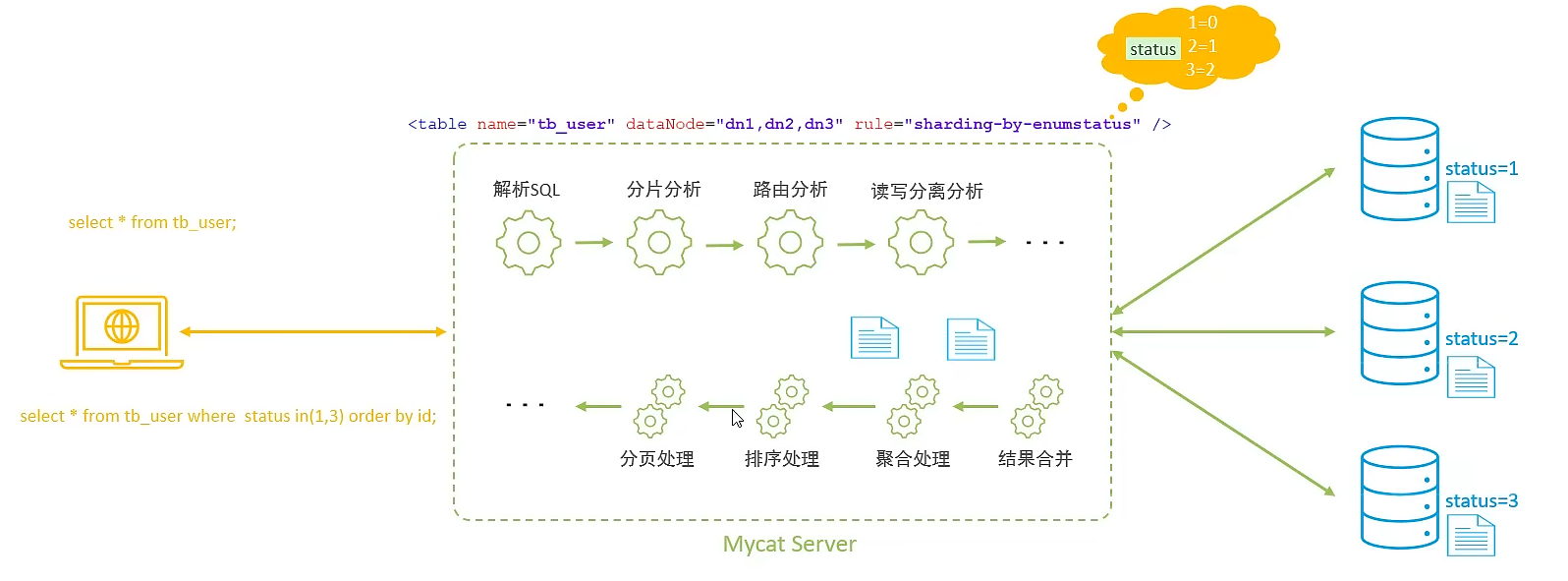
管理
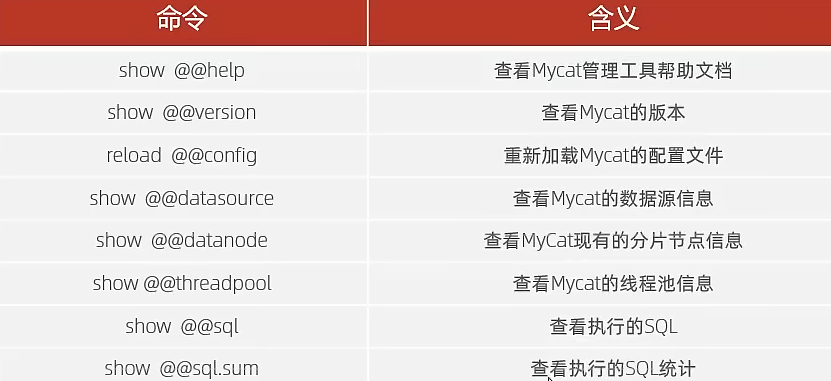
9066端口
1 | mysql -P 9066 -u root -p |
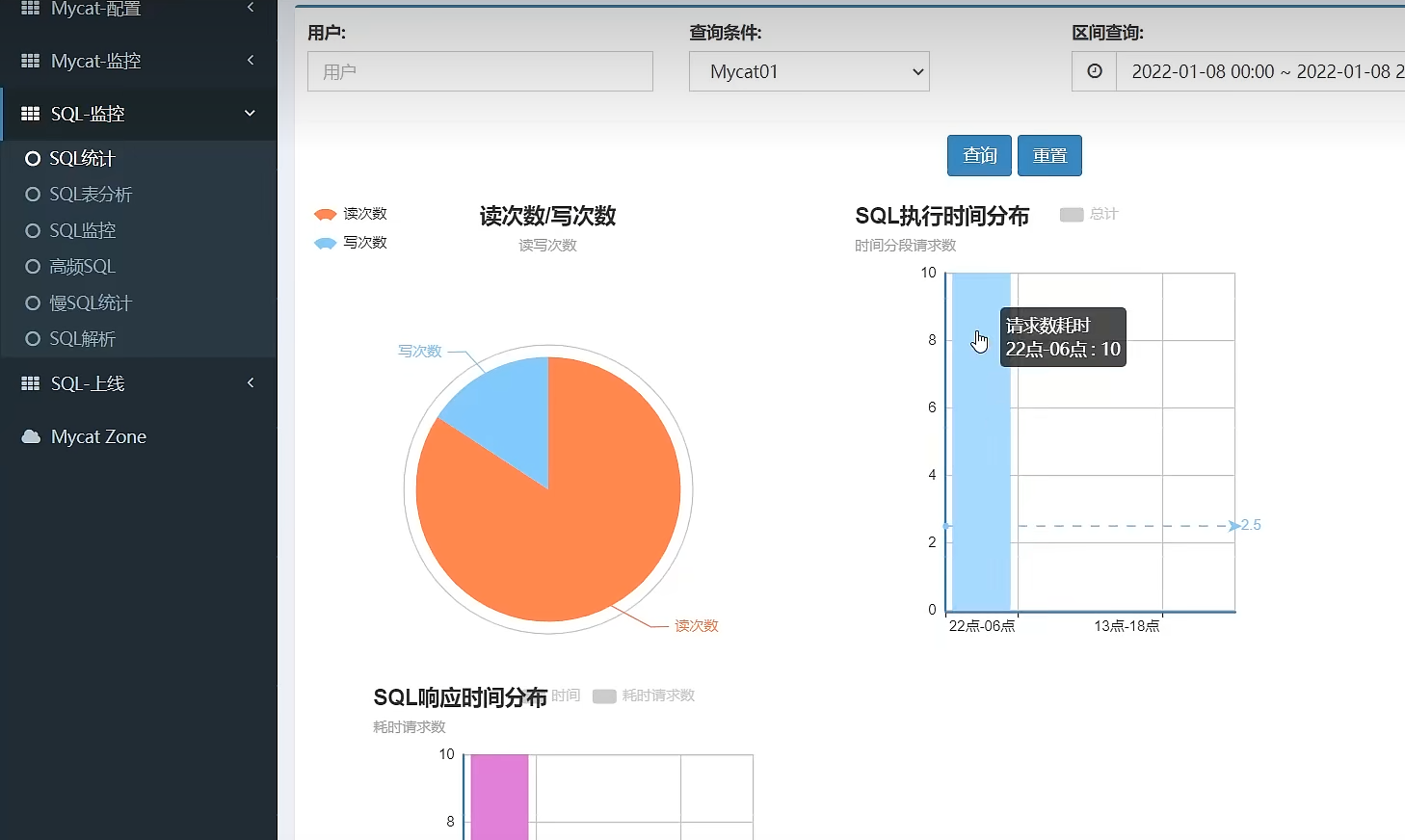
监控
mycateye工具可以以图形化形式监控mycat流量与sql性能
读写分离
读写分开,根据主从复制,主服务器写,从服务器读,减小压力
一主一从
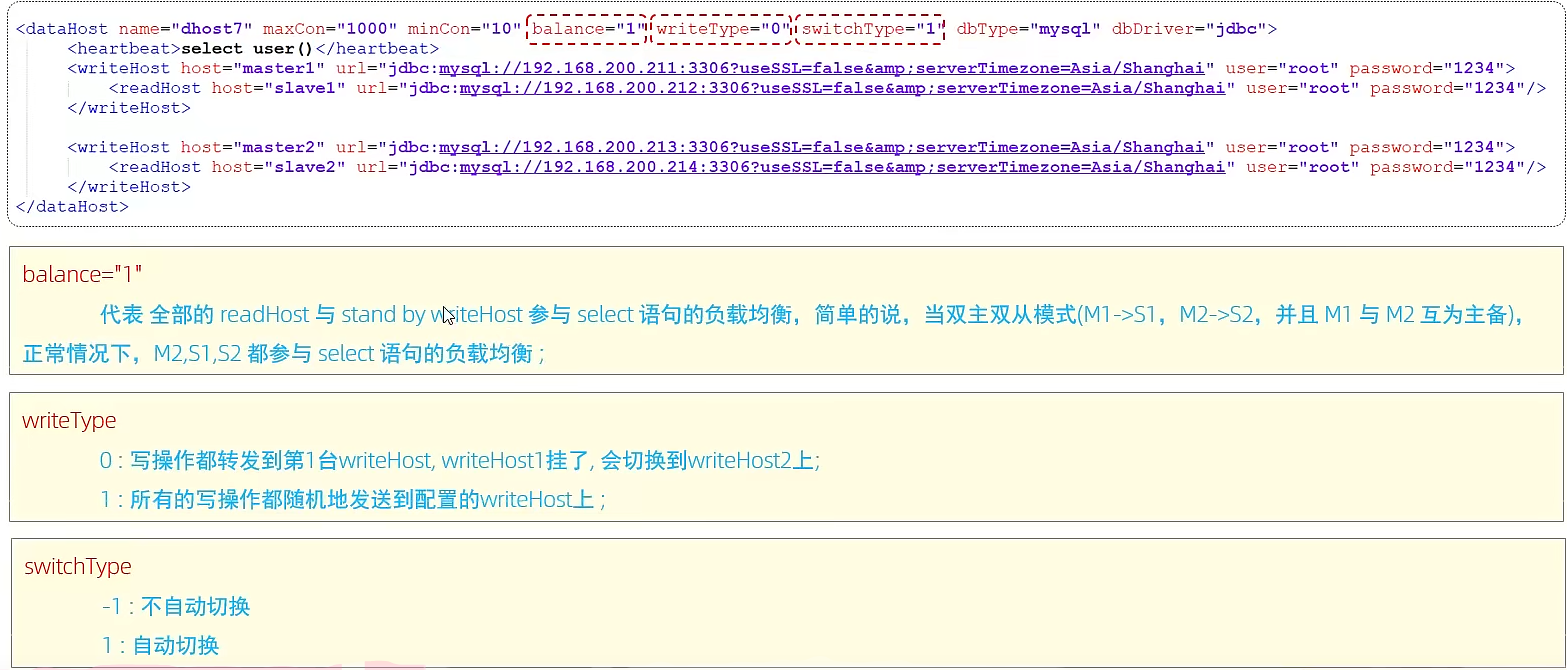
还是用mycat实现。balance属性设置负载均衡

问题:一旦主库宕机,所有的写操作都无法进行
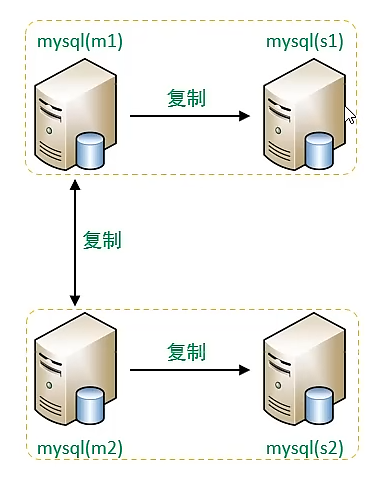
双主双从
master1负责写,master2、slave1、slave2负责读。当master1宕机,master2自动承担写的责任。
主库配置
- 配置my.cnf

重新启动mysql服务
创建用户并赋予权限

查看主库写入的文件位置
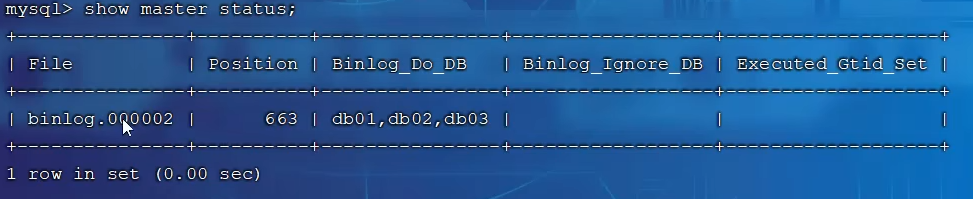
从库配置
修改my.cnf

重启mysql服务
配置主库
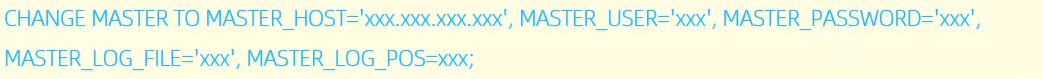
开启从库
配置mycat